Un développeur, 3 IA, zéro collision…
Depuis début 2026, je développe mes projets avec une équipe composée exclusivement d’agents IA. Claude Code orchestre, Codex CLI code le backend en TDD, Gemini CLI gère le fullstack Flutter. Le tout sur un simple filesystem, sans plateforme d’orchestration complexe.
Je m’appelle Philippe, je suis fondateur de AutomatisIA.fr. Depuis plusieurs mois, je pousse l’utilisation de Claude Code au-delà du simple « assistant de code ». Mon objectif : constituer une équipe de développement virtuelle capable de produire du code en parallèle, avec la même rigueur qu’une équipe humaine — contrats d’interface, code review, tests automatisés.
Dans cet article, je détaille ma configuration complète de Claude Code : les settings, les MCP servers originaux (NotebookLM comme RAG, N8N pour l’automatisation, Chrome pour le browser automation), le système de mémoire hybride SQLite, le workflow spec-driven, et surtout le protocole concret qui permet à 3 IA de coder en parallèle sans se marcher dessus.
Je partage aussi les chiffres réels, les coûts, et les échecs — parce que l’orchestration multi-agents, ce n’est pas que du « vibe coding ». C’est de l’ingénierie logicielle appliquée à l’IA.
1. Ma stack : 3 agents, 1 orchestrateur
L’idée n’est pas d’utiliser « une IA pour coder ». C’est de constituer une équipe de développement virtuelle où chaque agent a un rôle précis, des forces identifiées, et des règles d’engagement strictes.
L’organigramme
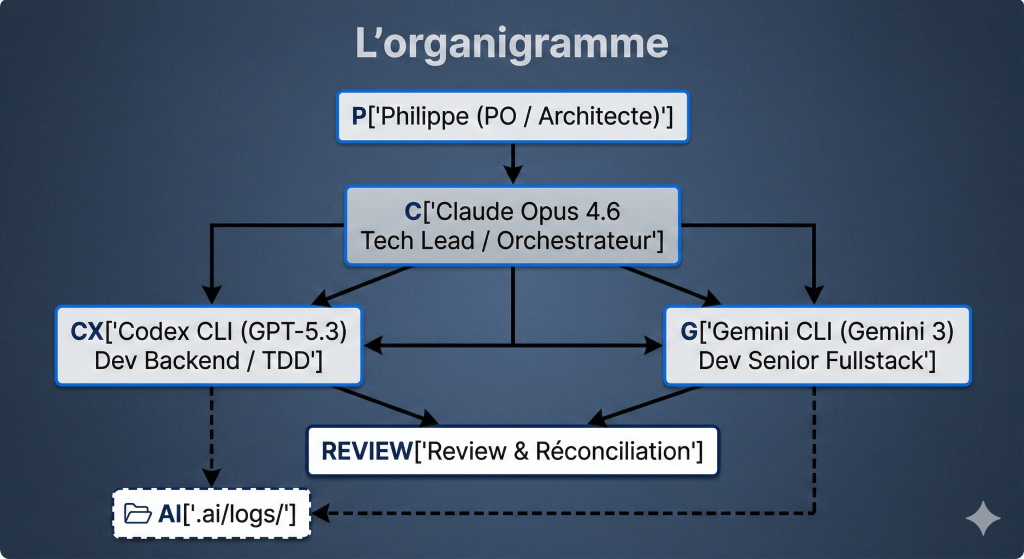
Tableau comparatif des agents
| Claude Opus 4.6 | Codex CLI (GPT-5.3) | Gemini CLI (Gemini 3) | |
|---|---|---|---|
| Rôle | Tech Lead / Orchestrateur | Dev Backend / TDD | Dev Senior Fullstack |
| SWE-bench | 80.8% | SOTA | 76.2% |
| Contexte | 1M tokens + compaction | Limité (workspace) | 1M tokens |
| Coût | Élevé (abonnement Max) | Inclus ChatGPT Pro | Gratuit (60 req/min) |
| Forces | Architecture, review, UI complexe (SwiftUI), réconciliation | TDD autonome, Edge Functions, refactoring ciblé | Flutter, services, git ops, docs, multimodal |
| CLI | claude (natif) |
codex exec --full-auto |
gemini -p "..." -y |
| Sandbox | Configurable | workspace-write (sécurisé) | Workspace limité |
Pourquoi 3 agents et pas un seul ?
Trois raisons :
- Parallélisation : pendant que Codex écrit les tests backend, Gemini génère les screens Flutter. Claude orchestre et review. Gain de temps réel.
- Gestion des quotas : Claude est le plus cher. Gemini est gratuit. Codex est inclus dans l’abonnement ChatGPT Pro. En répartissant, je maximise le débit sans exploser les coûts.
- Spécialisation : chaque modèle a des forces distinctes. Codex excelle en TDD autonome. Gemini gère le contexte long (1M tokens) et le multimodal. Claude prend les décisions architecturales.
2. Configuration de Claude Code
Claude Code est un CLI qui s’installe en local et qui transforme Claude en agent de développement autonome. Voici comment je l’ai configuré.
Settings globaux
Le fichier ~/.claude/settings.json définit les préférences globales :
{
"enabledPlugins": {
"swift-lsp@claude-plugins-official": true,
"clangd-lsp@claude-plugins-official": true
},
"language": "français",
"preferredNotifChannel": "terminal_bell"
}Points clés :
- Langue en français : Claude répond en français, nomme ses commits en français, commente en français. Ça paraît anodin, mais ça change le workflow quand on travaille seul.
- LSP plugins activés : Swift et C/C++ pour mes projets macOS. Claude Code supporte 11 language servers (TypeScript, Python, Rust, Go, Kotlin…).
- Notifications terminal : un
bellquand Claude finit une tâche longue. Combiné avec les hooks (voir ci-dessous).
Hooks : notifications macOS natives
Les hooks sont des commandes shell déclenchées par des événements Claude Code. J’en ai configuré deux dans ~/.claude/hooks.json :
{
"hooks": [
{
"event": "Notification",
"commands": [
"printf '\\a'",
"osascript -e 'display notification \"Notification\" with title \"Claude\" sound name \"Ping\"'"
]
},
{
"event": "Stop",
"commands": [
"printf '\\a'",
"osascript -e 'display notification \"Terminé\" with title \"Claude\" sound name \"Glass\"'"
]
}
]
}Quand Claude termine une tâche longue (génération de code, tests, review), je reçois une notification macOS native avec un son distinct. « Ping » pour les notifications intermédiaires, « Glass » pour la fin. Je peux lancer une tâche et passer sur un autre écran.
31 plugins, 22 skills
Claude Code a un système de plugins/marketplace. J’utilise 31 plugins officiels répartis en catégories :
- Language Servers (11) : TypeScript, Python, Swift, Rust, Go, C/C++, Kotlin, Java, C#, PHP, Lua — pour l’autocomplétion et l’analyse statique dans le terminal
- Workflow :
commit-commands,pr-review-toolkit,hookify,feature-dev - Qualité :
code-review,code-simplifier,security-guidance - Productivité :
skill-creator,plugin-dev,claude-md-management
En plus des plugins, j’ai 22 skills personnalisés installés sous forme de symlinks :
~/.claude/skills/
├── mobile-design -> ~/.agents/skills/mobile-design
├── ui-ux-pro-max -> ~/.agents/skills/ui-ux-pro-max
├── ai-agents-architect -> ~/.agents/skills/ai-agents-architect
├── supabase-automation -> ~/.agents/skills/supabase-automation
├── stripe-integration -> ~/.agents/skills/stripe-integration
├── firebase -> ~/.agents/skills/firebase
├── swiftui-expert-skill -> ~/.agents/skills/swiftui-expert-skill
├── frontend-design -> ~/.agents/skills/frontend-design
├── nestjs-expert -> ~/.agents/skills/nestjs-expert
└── ... (13 autres)Chaque skill est un fichier markdown qui injecte des instructions spécialisées quand Claude détecte un contexte pertinent. Par exemple, swiftui-expert-skill s’active automatiquement quand je travaille sur du code SwiftUI et injecte les best practices iOS 26+, la gestion du state, et les patterns Liquid Glass.
Configuration projet : CLAUDE.md et permissions par projet
Au-delà des settings globaux, Claude Code permet une configuration par projet. Chaque répertoire de projet peut contenir un fichier CLAUDE.md qui injecte des directives spécifiques à ce projet dans chaque conversation.
Par exemple, le CLAUDE.md du projet OptimisIA.app contient les contraintes Swift 6, l’architecture MVVM, et les dépendances autorisées. Celui de NeuralPro.fr contient les conventions Flutter, les patterns Riverpod, et les règles de sécurité Supabase.
Combiné avec des settings.local.json par projet (permissions Bash spécifiques, domaines WebFetch autorisés), cela crée un environnement de développement contextualisé : quand je cd dans un projet et lance Claude Code, il sait déjà quelles technologies utiliser, quelles règles suivre, et quels outils il a le droit d’appeler.
C’est cette granularité qui rend la configuration de Claude Code si puissante : les settings globaux définissent les préférences générales, les skills injectent l’expertise technique, et les fichiers projet définissent le contexte métier.
3. Mes MCP originaux : NotebookLM, N8N, Claude-in-Chrome
Les MCP servers (Model Context Protocol) sont le mécanisme d’extension de Claude Code. Ils permettent de connecter Claude à des services externes via un protocole standardisé. J’en ai 14 configurés, mais trois sont particulièrement originaux.
NotebookLM comme RAG maison
C’est probablement l’usage le plus atypique de ma configuration. Google NotebookLM, normalement un outil de prise de notes IA, devient ici une base de connaissances interrogeable par Claude Code.
Le principe :
- Je crée des notebooks thématiques dans NotebookLM (documentation technique, specs projet, articles de référence, PDFs de design…)
- NotebookLM indexe et « comprend » ces documents grâce à Gemini
- Le MCP
notebooklmexpose des outils commeask_question,search_notebooks,list_notebooks - Claude Code peut interroger cette base en langage naturel pendant qu’il code
Cas d’usage concret : quand Claude travaille sur l’intégration Ayrshare pour NeuralPro.fr, il peut demander à NotebookLM : « Quelles sont les limites de l’API Ayrshare pour la publication multicanal ? » et obtenir une réponse synthétisée à partir de la documentation que j’ai importée, sans consommer de tokens Claude pour lire 50 pages de docs.
C’est un RAG du pauvre — pas de vector store, pas d’embeddings custom — mais c’est gratuit, rapide à alimenter, et suffisant pour 90% de mes besoins de contexte documentaire.
Pourquoi NotebookLM plutôt qu’un vrai RAG ? Trois raisons : (1) zéro infrastructure à maintenir, (2) l’indexation est automatique quand j’ajoute un document, (3) la qualité des réponses est excellente grâce à Gemini en backend. Pour un développeur solo, c’est le meilleur ratio effort/valeur que j’ai trouvé pour donner du contexte documentaire à Claude sans polluer sa fenêtre de contexte.
En pratique, je maintiens 4-5 notebooks thématiques : un par projet (NeuralPro, OptimisIA), un pour les docs d’API tierces (Supabase, Ayrshare, Stripe), et un « general knowledge » avec mes articles de référence sur l’architecture logicielle.
Outils NotebookLM disponibles :
- add_notebook → Ajouter un notebook/source
- ask_question → Interroger la base en langage naturel
- search_notebooks → Recherche par mots-clés
- select_notebook → Choisir le notebook actif
- list_notebooks → Lister les notebooks disponibles
- get_library_stats → Stats d'utilisationN8N : l’automatisation qui complète Claude
J’utilise deux instances N8N connectées via MCP : une pour mon infrastructure personnelle (Hostinger), une pour les projets clients.
N8N est un outil d’automatisation low-code. Connecté à Claude Code via MCP, il permet de :
- Créer des workflows d’automatisation directement depuis le terminal Claude (
n8n_create_workflow) - Debugger des workflows existants (
n8n_autofix_workflow) - Tester et déployer des templates (
n8n_test_workflow,n8n_deploy_template) - Consulter les exécutions passées pour diagnostiquer des erreurs (
n8n_executions)
Cas d’usage concret : je demande à Claude « Crée un workflow N8N qui surveille les nouvelles issues GitHub sur le repo NeuralPro et envoie un résumé Slack quotidien ». Claude utilise le MCP pour créer le workflow, le valider, et le tester — sans que je quitte le terminal.
Outils N8N disponibles :
- n8n_create_workflow → Créer un workflow complet
- n8n_update_workflow → Modifier un workflow existant
- n8n_autofix_workflow → Corriger automatiquement les erreurs
- n8n_test_workflow → Exécuter un test
- n8n_validate_workflow → Valider la structure
- n8n_deploy_template → Déployer un template
- n8n_executions → Consulter l'historique
- search_nodes → Chercher des nœuds disponibles
- search_templates → Chercher des templatesClaude-in-Chrome : le browser automation intégré
Le MCP claude-in-chrome donne à Claude le contrôle d’un navigateur Chrome. Pas via Playwright (que j’ai aussi), mais directement dans mon navigateur actif, avec mes sessions, mes cookies, mes onglets ouverts.
Les capacités :
- Navigation et lecture :
navigate,read_page,get_page_text - Interaction :
form_input,find(sélecteurs CSS),computer(clicks, scrolls) - Debug :
read_console_messages,read_network_requests,javascript_tool - Capture :
gif_creatorpour enregistrer des séquences d’interaction en GIF - Gestion d’onglets :
tabs_context_mcp,tabs_create_mcp
Cas d’usage concret : je teste le dashboard Supabase de NeuralPro.fr. Je demande à Claude : « Va sur le dashboard Supabase, vérifie que la table posts a bien les colonnes attendues, et fais-moi un GIF de la navigation. » Claude ouvre l’onglet, navigue, lit le DOM, capture un GIF, et me rapporte le résultat — le tout dans le terminal.
C’est particulièrement utile pour :
- Vérifier des déploiements visuellement sans quitter le terminal
- Automatiser des tests end-to-end sur des interfaces authentifiées
- Capturer des preuves visuelles (GIF) pour la documentation ou les PR
- Scraper du contenu web en contexte authentifié (dashboards, back-offices)
La différence avec Playwright (que j’ai aussi en MCP) : Playwright lance un navigateur headless séparé. Claude-in-Chrome utilise mon Chrome avec mes sessions actives. C’est crucial quand on travaille avec des services qui nécessitent une authentification complexe (SSO, 2FA) — je me connecte une fois dans Chrome, et Claude peut ensuite naviguer librement dans mes dashboards.
Et les 11 autres MCP ?
Pour être complet, voici les autres MCP configurés. Ils sont moins originaux (ce sont des intégrations « standard ») mais ils complètent l’écosystème :
| MCP | Type | Usage principal |
|---|---|---|
| GitHub | HTTP | Issues, PRs, repos — le coeur du workflow git |
| Supabase | HTTP | Gestion base de données, migrations, Edge Functions |
| Context7 | NPX | Documentation technique à jour (alternative au web search) |
| Slack | HTTP + OAuth | Notifications, résumés de channels |
| Linear | HTTP | Issue tracking pour les projets structurés |
| Stripe | HTTP | Gestion paiements et abonnements |
| Firebase | NPX | Auth, Firestore, Cloud Functions |
| Playwright | NPX | Tests E2E headless (complémentaire à Chrome) |
| GitLab | HTTP | Repos clients hébergés sur GitLab |
| Hostinger | HTTP | Gestion VPS, DNS, domaines |
| Serena | UVX | Serveur MCP custom Python |
Le point clé : tous ces MCP fonctionnent ensemble. Dans une seule conversation, Claude peut créer une issue GitHub, vérifier la base Supabase, chercher dans la doc Context7, et m’envoyer un résumé sur Slack. C’est cette combinaison qui rend le workflow puissant.
4. Le système de mémoire hybride
Claude Code a un mécanisme de mémoire persistante : un fichier MEMORY.md auto-injecté dans chaque conversation. Le problème ? Il grossit. Après quelques projets, mon MEMORY.md faisait 90+ lignes et consommait du contexte inutilement à chaque échange.
La solution : 3 couches de mémoire
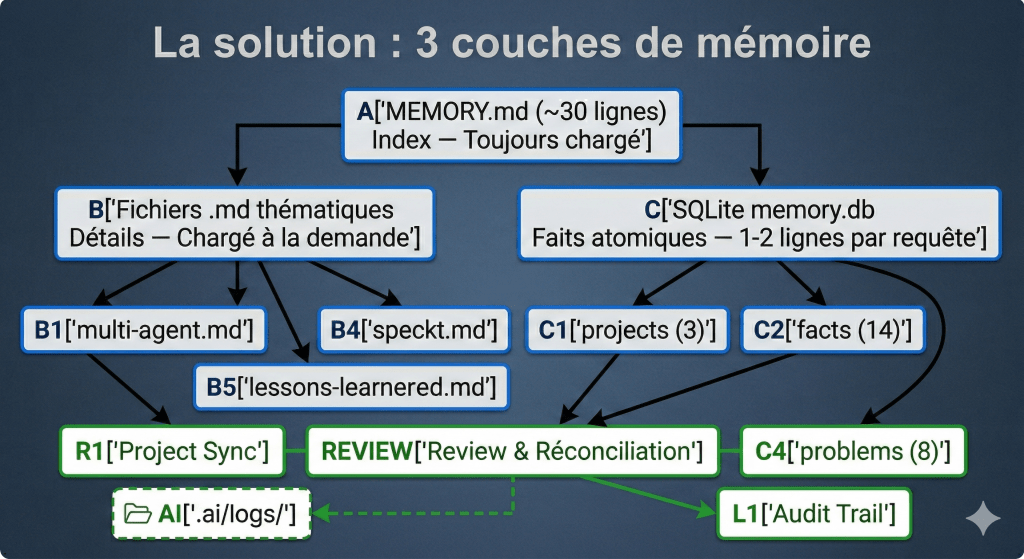
Couche 1 : MEMORY.md = index de routage (~30 lignes)
Le seul fichier auto-injecté. Il contient uniquement :
- Un tableau des projets (nom, chemin, stack, lien vers le fichier détaillé)
- Un tableau des fichiers thématiques
- Le chemin vers la base SQLite + les requêtes types
- 3 lignes de conventions globales
# Project Memory — Index
## Projets
| Projet | Dossier | Stack | Détails |
|--------|---------|-------|---------|
| NeuralPro.fr | /chemin/neuralpro/ | Flutter+Supabase | memory/neuralpro.md |
| OptimisIA.app | /chemin/optimisia/ | SwiftUI macOS | memory/optimisia.md |
## Base SQLite
- memory/memory.db — Faits atomiques, décisions, problèmes résolus
- Requêter : sqlite3 memory.db "SELECT value FROM facts WHERE key='...'"
## Conventions globales
- Chemins ABSOLUS dans tous les prompts agents
- Un fichier = un agent (jamais d'écriture concurrente)
- Gemini : TOUJOURS -y | Codex : --skip-git-repo-check hors gitRésultat : chaque conversation démarre avec ~30 lignes de contexte au lieu de 90+. Claude sait où chercher, sans tout charger.
Couche 2 : fichiers .md thématiques (chargés à la demande)
Quand Claude a besoin de détails sur un sujet, il fait un Read sur le fichier correspondant :
| Fichier | Contenu |
|---|---|
multi-agent.md |
Architecture, commandes CLI, protocoles, règles d’or, allocation |
speckit.md |
Workflow Spec-Driven Development |
lessons-learned.md |
Rétrospectives, patterns validés, anti-patterns |
neuralpro.md |
Projet NeuralPro.fr (stack, leçons Supabase, déploiement) |
optimisia.md |
Projet OptimisIA.app / Proza (résultats, métriques) |
Couche 3 : SQLite pour les faits atomiques
Pour les informations précises (un token, une commande, un bug résolu), une base SQLite est plus efficace qu’un fichier markdown :
-- Schéma
CREATE TABLE facts (
project_id TEXT, key TEXT, value TEXT, category TEXT,
UNIQUE(project_id, key)
);
CREATE TABLE decisions (
project_id TEXT, title TEXT, decision TEXT, reason TEXT
);
CREATE TABLE problems (
project_id TEXT, description TEXT, solution TEXT, tags TEXT
);
-- Exemples de requêtes que Claude exécute
SELECT value FROM facts WHERE key = 'gemini_model_stable';
-- → "gemini-2.5-flash"
SELECT solution FROM problems WHERE tags LIKE '%supabase%';
-- → Toutes les solutions aux problèmes Supabase
SELECT decision, reason FROM decisions WHERE project_id = 'neuralpro';
-- → Toutes les décisions architecturales du projetLe coût en contexte ? 1 à 2 lignes par requête, au lieu de charger un fichier entier.
Workflow : quand utiliser quelle couche
| Besoin | Couche | Exemple |
|---|---|---|
| Fait précis | SQLite | « Quel modèle Gemini utiliser ? » → SELECT value FROM facts WHERE key='gemini_model_stable' |
| Contexte large | Fichier .md | « Comment fonctionne l’orchestration ? » → Read multi-agent.md |
| Recherche floue | Grep sur .md | « On avait un bug JWT » → Grep 'JWT' memory/*.md |
| Nouveau fait | SQLite INSERT | INSERT INTO facts VALUES ('neuralpro', 'api_version', 'v2', 'api') |
5. Spec-Driven Development avec Spec-Kit
Avant de dispatcher du code aux agents, il faut spécifier ce qu’on veut. J’utilise Spec-Kit (par GitHub), un outil CLI qui structure le passage de l’idée au code en 9 étapes.
Le workflow en 9 étapes
1. specify init neuralpro --ai claude --ai-skills → Scaffold projet + skills Claude
2. /speckit.constitution → Principes fondateurs du projet
3. /speckit.specify → User stories, exigences fonctionnelles
4. /speckit.clarify → Lever les ambiguïtés (optionnel)
5. /speckit.plan → Plan technique (data model, archi)
6. /speckit.tasks → Découper en tâches actionnables
7. /speckit.checklist → Validation qualité (optionnel)
8. /speckit.analyze → Cohérence inter-artefacts (optionnel)
9. /speckit.implement → Exécution du codeChaque étape produit un fichier markdown dans un dossier specs/ structuré :
specs/001-neuralpro-mvp/
├── spec.md ← User stories, critères d'acceptation
├── plan.md ← Plan technique, data model
├── tasks.md ← Tâches actionnables (prêtes pour dispatch)
├── contracts/
│ ├── generate-post.md ← Contrat Edge Function (endpoint, payload, réponse)
│ └── publish-post.md ← Contrat Edge Function
├── data-model.md ← Schéma base de données
├── research.md ← Recherche technique (APIs, alternatives)
└── checklists/ ← Validation qualitéLa « constitution » de projet
L’étape la plus originale de Spec-Kit. La constitution est un document qui fixe les principes non-négociables du projet. Pour NeuralPro.fr :
# Constitution NeuralPro.fr (v1.0.0)
## Principes fondateurs
I. Zero Friction (< 45 secondes)
Le temps entre l'ouverture de l'app et la publication finale
DOIT être inférieur à 45 secondes.
II. Secrets Server-Side Only (NON-NÉGOCIABLE)
Le frontend Flutter ne DOIT JAMAIS contenir de clés API.
Tous les appels tiers passent par les Edge Functions Supabase.
III. Offline-Tolerant, Cloud-Native
Photo + saisie vocale fonctionnent hors connexion.
Upload + génération IA au retour de la connectivité.
IV. Test-First & Contract-Driven
Les contrats Edge Function sont la source de vérité.
Les tests d'intégration valident les payloads contre les contrats.
V. Simplicity & MVP Discipline
MVP livrable en < 30 jours.
Data model limité à 2 tables (users, posts).
Principe YAGNI : pas d'abstraction sans besoin immédiat.Cette constitution est injectée dans le briefing de chaque agent. Si Codex ou Gemini produisent du code qui viole un principe, Claude (orchestrateur) le détecte au review.
Intégration avec les agents externes
C’est là que Spec-Kit et l’orchestration multi-agents se rejoignent :
- Les specs (
spec.md) et le plan (plan.md) servent de briefing initial - Les contrats (
contracts/*.md) deviennent les interfaces entre agents - Les tâches (
tasks.md) sont dispatchées par agent selon la stratégie d’allocation - La constitution est le garde-fou que Claude vérifie à chaque review
6. L’orchestration multi-agents en pratique
C’est le coeur du système. Comment faire travailler 3 IA en parallèle sur le même projet sans qu’elles se marchent dessus ?
Le bus filesystem : .ai/
Pas de plateforme d’orchestration, pas d’API complexe. Un simple dossier .ai/ à la racine du projet :
projet/.ai/
├── state.json ← État global, locks par fichier
├── context/ ← Briefings entrants (un par agent)
│ ├── codex-brief.md
│ └── gemini-brief.md
├── contracts/ ← Interfaces (versionnées dans git)
│ ├── api-endpoints.md
│ └── module-interfaces.ts
├── logs/ ← Sorties brutes capturées
│ ├── codex-output-001.txt
│ └── gemini-output-001.txt
└── reviews/ ← Résultats de reviewC’est simple, debuggable, et ne dépend d’aucun service externe. Si quelque chose ne va pas, je lis un fichier. Pas besoin de dashboard.
Le protocole de lancement (checklist obligatoire)
AVANT de dispatcher un agent :
[x] 1. Smoke test : l'agent peut-il écrire un fichier ?
[x] 2. Briefing complet dans .ai/context/.md
[x] 3. Contrats d'interface dans .ai/contracts/
[x] 4. Chemins ABSOLUS dans le prompt
[x] 5. Flag d'écriture actif (Gemini: -y, Codex: --full-auto)
[x] 6. Output capture configuré (-o fichier ou redirection)
APRÈS le retour de l'agent :
[x] 7. Vérifier que les fichiers attendus existent
[x] 8. Build du projet
[x] 9. Tests
[x] 10. Review du code avant intégrationLe smoke test (point 1) est la leçon la plus douloureuse que j’ai apprise. Sur un projet, j’ai dispatché Gemini sans le flag -y. Résultat : 0% de contribution, mode lecture seule, mission perdue. Le smoke test aurait détecté ça en 5 secondes.
Les 6 règles d’or
Règle 1 : JAMAIS deux agents sur le même fichier en parallèle.
Conséquence de violation : perte silencieuse de code (le dernier qui écrit gagne).
Règle 2 : Git = toujours séquentiel, APRÈS l’écriture complète.
Pas de git add pendant qu’un agent écrit. Pas de push pendant un review.
Règle 3 : Valider chaque sortie d’agent avant de chaîner.
Si Codex produit du code buggé, Gemini ne doit pas construire dessus.
Règle 4 : Chemins ABSOLUS dans tous les prompts agents.
Les agents n’ont pas le même working directory. Un chemin relatif = bug garanti.
Règle 5 : Contrats d’interface AVANT le codage parallèle.
Sans contrat, chaque agent invente ses propres types/signatures.
Règle 6 : Un briefing = une mission. Pas de scope creep.
Si la mission évolue, on arrête l’agent et on relance avec un nouveau briefing.
Pattern de décomposition
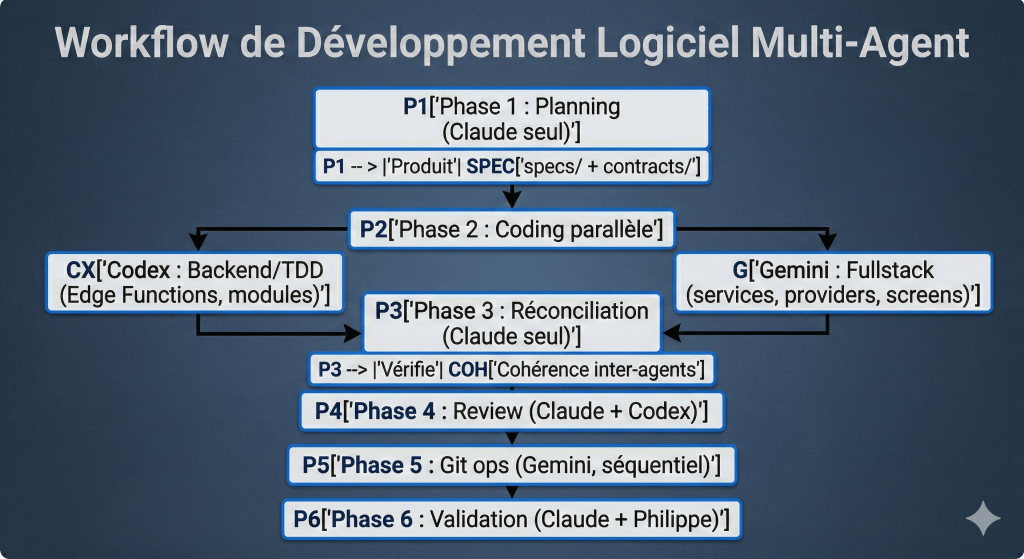
Le point critique : la phase 2 est la seule phase parallèle. Tout le reste est séquentiel. Et même en phase 2, chaque agent a ses fichiers assignés — jamais de chevauchement.
Commandes types par agent
# Codex : implémentation backend en TDD
codex exec --full-auto -m gpt-5.3-codex \
-C /chemin/projet/backend \
-o .ai/logs/codex-output-001.txt \
"$(cat .ai/context/codex-brief.md)"
# Codex : code review
codex review --uncommitted -m gpt-5.3-codex
# Gemini : services fullstack
gemini -p "$(cat .ai/context/gemini-brief.md)" -y
# Gemini : modèle spécifique (raisonnement avancé)
gemini -m pro -p "Analyse cette architecture et propose des améliorations" -yFallback chain
Quand un agent est saturé ou échoue, le fallback est immédiat :
| Mission | Primaire | Secondaire | Tertiaire |
|---|---|---|---|
| Codage fullstack | Gemini | Codex | Claude (direct) |
| Backend / TDD | Codex | Gemini | Claude (direct) |
| Git / DevOps | Gemini | Claude (Bash) | — |
| Docs / i18n | Gemini | Codex | Claude |
| Review | Claude | Codex review | Gemini |
Principe : ne jamais debugger un agent qui échoue. On bascule sur le fallback, on log l’échec, et on post-mortem après.
7. Cas concrets : 3 projets, 3 patterns
Proza : Le premier projet multi-agent
Proza est un éditeur Markdown pour macOS, développé en SwiftUI et publié sur l’App Store en février 2026. C’est le premier projet où j’ai testé l’orchestration multi-agents.
Allocation :
- Claude : architecture, contrats d’interface, SwiftUI (views), réconciliation
- Codex : module Core en TDD (parseur Markdown, convertisseurs DOCX/PDF/Spreadsheet)
- Gemini : git operations, i18n, documentation
Résultats chiffrés :
- 4 273 lignes de code produites en parallèle
- Zéro collision entre agents (grâce à la règle un fichier = un agent)
- Codex : 32 tests unitaires, 100% pass, 1 847 lignes, une seule exécution
- Temps total de développement significativement réduit par rapport à un dev solo
La rétrospective de Proza a produit les « 6 règles d’or » et le protocole de lancement que j’utilise maintenant sur tous mes projets.
NeuralPro.fr : NextJS + Supabase + Gemini Flash
NeuralPro.fr est un SaaS pour professionnels : Un agent IA qui aide les commerciaux a faire leur prospection en ellant cherchez toutes les informations disponibles sur une entreprise (OpenAI, Perplexity, Pappers…)
Allocation (pattern évolué) :
- Claude : architecture + spec-kit + review + réconciliation
- Gemini : services NextJS, providers, screens (rôle élevé = Dev Senior fullstack)
- Codex : Edge Functions backend en TDD (Deno/TypeScript)
Le changement par rapport à Proza : Gemini est passé de « git ops » à « Dev Senior fullstack ». Avec Gemini 3.1 Pro et son raisonnement avancé, il gère désormais les services complexes, les providers avec state management, et les screens avec widgets.
Exemple de contrat inter-agents :
# Contrat : generate-post (Edge Function)
Endpoint : POST /functions/v1/generate-post
Auth : Bearer JWT Supabase
Request :
image_path: string → "{user_id}/{filename}.jpg"
raw_context: string → Saisie vocale/texte (1-500 chars)
company_name: string → Personnalisation (1-100 chars)
Response 200 :
post_id: uuid
generated_text: string
generation_count: number
Ce contrat est la SOURCE DE VÉRITÉ.
Codex implémente l'Edge Function.
Gemini implémente le service qui l'appelle.Grâce à ce contrat, Codex et Gemini ont codé en parallèle sans jamais se parler — et l’intégration a fonctionné du premier coup.
Les leçons spécifiques à NeuralPro.fr :
- JWT ES256 vs HS256 : Supabase a migré ses JWTs vers ES256, mais le relay des Edge Functions ne les reconnaissait pas. Solution : déployer avec
--no-verify-jwtet vérifier le JWT dans le code de la fonction viagetUser(). - Storage paths : le service retournait l’URL publique complète au lieu du path relatif. L’Edge Function attendait un path (
userId/filename.jpg). Deux agents, deux conventions — le contrat aurait dû spécifier le format exact. - Modèle Gemini API :
gemini-2.0-flasha été déprécié pendant le développement. Migration versgemini-2.5-flashen urgence.
Chaque problème résolu a été enregistré dans la base SQLite (table problems) pour ne plus le reproduire. C’est la boucle de feedback du système de mémoire hybride en action.
Proza sur l’App Store
Proza, a été soumis sur l’App Store le 14 février 2026. Le processus de soumission a lui-même été partiellement géré par les agents :
- Claude a géré les entitlements App Sandbox et la configuration Xcode
- Gemini a produit les métadonnées App Store (descriptions, keywords, catégorisation)
- Le build final a été validé par le protocole standard : build + tests + review
8. Combien ça coûte ?
La transparence sur les coûts est importante. Voici la réalité de cette stack multi-agents en mars 2026 :
| Service | Coût mensuel | Notes |
|---|---|---|
| Claude Code (Max) | 100 $/mois | Le plus cher. Opus 4.6 consomme beaucoup de tokens. Le plan Max est nécessaire pour un usage intensif. |
| ChatGPT Plus (Codex inclus) | 25 $/mois | Codex CLI est inclus dans l’abonnement Pro. Pas de coût additionnel par token. |
| Gemini CLI | 20€ | Integré à mon abonnement Google Workspace. Largement suffisant. C’est l’agent principal pour le codage. |
| Supabase | 0 $/mois | Free tier pour le dev, Pro pour la prod. |
| N8N | 0 $/mois | Self-hosted. |
| NotebookLM | 0 $ | Gratuit (Google). |
| Autres MCP (GitHub, Slack, Linear…) | 0 $ | Free tiers ou inclus dans les abonnements existants. |
Total estimé : 150 $/mois
C’est le coût d’un développeur freelance à mi-temps pendant 2-3 heures. Pour une équipe de 3 agents IA disponibles 24/7, c’est un ratio très favorable.
La stratégie d’optimisation :
- Gemini en agent principal (gratuit) pour tout le codage fullstack
- Codex en missions ciblées (TDD backend) pour maximiser le ChatGPT Pro
- Claude réservé aux décisions architecturales, review, et réconciliation — là où sa supériorité justifie le coût
9. Limites et échecs honnêtes
L’orchestration multi-agents n’est pas magique. Voici ce qui ne marche pas (encore) parfaitement.
Gemini sans -y : la mission perdue
Sur Proza, j’ai dispatché Gemini avec gemini -p "..." sans le flag -y. Sans ce flag, Gemini fonctionne en mode lecture seule : il analyse, il propose, mais il n’écrit rien. Résultat : 0% de contribution, temps perdu, fallback sur Claude qui a dû absorber la mission.
Leçon : le smoke test pré-mission aurait détecté ça en 5 secondes. Depuis, c’est obligatoire.
Les modèles dépréciés sans prévenir
Google a déprécié gemini-2.0-flash puis gemini-3.1-pro-preview sans avertissement clair. Un beau matin, l’agent retourne une 404. Il faut alors :
- Identifier l’erreur (pas toujours évident dans les logs)
- Trouver le modèle de remplacement
- Mettre à jour tous les briefings et la mémoire
Leçon : ne jamais hardcoder un modèle spécifique. Utiliser les alias stables (pro, flash) ou le mode Auto.
Le temps d’orchestration
Préparer un briefing, écrire un contrat, configurer les chemins, lancer le smoke test, capturer l’output, review le code… L’orchestration prend du temps. Pour une tâche de 30 minutes de code, l’overhead d’orchestration peut représenter 15-20 minutes.
L’orchestration multi-agents n’est rentable que pour des tâches de taille moyenne à grande (>2h de code). Pour un bugfix de 3 lignes, c’est plus rapide de le faire soi-même dans Claude Code.
La divergence de contexte
Chaque agent a son propre contexte. Codex ne sait pas ce que Gemini a produit. Si les contrats ne sont pas assez précis, les agents produisent des implémentations techniquement correctes mais incompatibles entre elles.
Leçon : les contrats doivent être aussi précis qu’une API spec OpenAPI. Types exacts, exemples de payloads, cas d’erreur documentés.
Le Gemini sandbox
Gemini CLI ne peut pas écrire en dehors de son workspace. Si on a besoin qu’il modifie un fichier à la racine du projet, il faut soit rediriger son output, soit faire écrire Claude. C’est une friction supplémentaire dans l’orchestration.
Ce que je ferais différemment
- Commencer par 2 agents, pas 3. Claude + Gemini suffisent pour 80% des cas. Ajouter Codex quand le pattern est maîtrisé.
- Automatiser le smoke test. Un script qui vérifie en 10 secondes que chaque agent peut lire/écrire/exécuter.
- Versionner les contrats dès le premier commit. Sur Proza, on a oublié — perte de traçabilité.
- Mesurer les tokens par mission. Sans métriques, impossible d’optimiser l’allocation.
10. Conclusion
Après 3 projets et plusieurs mois d’itération, voici ce que je retiens de cette configuration :
Ce qui marche :
- La spécialisation des agents par force (Claude = archi, Codex = TDD, Gemini = fullstack) est plus efficace qu’un seul agent qui fait tout
- Le filesystem comme bus de communication est simple, debuggable, et suffisant
- Les contrats d’interface avant le codage parallèle éliminent les conflits d’intégration
- La mémoire hybride (index + fichiers + SQLite) résout le problème du contexte qui grossit
- Les MCP servers (NotebookLM, N8N, Chrome) étendent Claude bien au-delà du code
Les principes à retenir si vous voulez reproduire ce setup :
- Un fichier = un agent. C’est la règle qui élimine 90% des problèmes.
- Spécifiez avant de coder. Spec-Kit ou pas, les contrats sont non-négociables.
- Smoke test avant chaque mission. 5 secondes qui économisent des heures.
- Commencez petit. 2 agents suffisent. Ajoutez le troisième quand le protocole est rodé.
- Mesurez. Sans métriques (tokens, lignes, temps), impossible d’optimiser.
Le « vibe coding » multi-agents n’est pas de la magie — c’est de l’ingénierie d’orchestration. Mais une fois le protocole en place, la productivité est réelle : 4 273 lignes en parallèle, zéro collision, des tests qui passent du premier coup.
Si vous avez des questions sur cette configuration ou si vous voulez adapter ce setup à vos projets, contactez-moi sur AutomatisIA.fr. Je partage régulièrement mes retours d’expérience sur l’IA appliquée au développement dans la section Actualités IA.
Pour aller plus loin :
- Documentation officielle Claude Code
- Spec-Kit sur GitHub
- Model Context Protocol (MCP) — Documentation
Philippe, Fondateur de AutomatisIA.fr — Mars 2026
Cet article fait partie de la série Actualités IA.