RAG : On commence…
Les modèles de langage de grande taille (LLMs) ont révolutionné notre façon d’appréhender et de générer l’information. Cependant, leur application directe se heurte à deux écueils majeurs : l’accès limité aux données les plus récentes et la génération de réponses erronées, communément appelées « hallucinations ».
C’est là qu’intervient le Retrieval Augmented Generation (RAG), une approche novatrice qui permet de surmonter ces obstacles en dotant les LLMs de la capacité à produire des réponses précises et actualisées. Le RAG s’impose comme un levier d’innovation incontournable pour les entreprises souhaitant tirer pleinement parti du potentiel des LLMs.
Anatomie du RAG : Un mariage parfait entre Retrieval et Generation
Le RAG s’articule autour de deux composantes essentielles : la récupération de données pertinentes (Retrieval) et la génération de contenu (Generation). Plongeons au cœur de ces processus pour comprendre comment ils s’imbriquent et quels outils permettent une implémentation optimale.
Retrieval : L’art de poser la bonne question
L’étape de retrieval est cruciale, car elle conditionne la qualité des informations qui serviront de base à la génération des réponses. Pour bâtir une base de données vectorielle robuste, PostgreSQL est souvent plébiscité pour sa fiabilité et sa capacité à gérer de grands volumes de données. Elasticsearch, quant à lui, brille par sa rapidité de recherche textuelle et est couramment utilisé pour des requêtes complexes.
Des solutions spécialisées comme Chroma et Pinecone offrent des fonctionnalités avancées pour les bases de données vectorielles, permettant une recherche par similarité ultra-performante. L’utilisation de ces systèmes contribue à filtrer les données les plus pertinentes en réponse à une requête donnée.
Génération : La Créativité Encadrée
Une fois les données pertinentes récupérées, place à la génération ! Les LLMs tels que GPT-4 ou des alternatives comme Claude 3 ou Mixtral 8x7b entrent en scène pour générer des réponses cohérentes et riches en informations.
La génération est améliorée par des techniques de « prompt engineering » qui guident le modèle pour qu’il réponde dans un format et un style adaptés, tout en s’appuyant sur les données contextualisées fournies.
Le RAG en Action : Des Cas d’Usage Concrets
Le RAG trouve des applications dans de nombreux domaines, démontrant sa polyvalence et sa valeur ajoutée :
- E-commerce : Génération de descriptions de produits personnalisées et de recommandations ultra-pertinentes.
- Finance : Détection de fraudes et prédiction de tendances de marché basées sur des données financières en temps réel.
- Service Client : Assistance automatisée offrant des réponses précises et actualisées aux requêtes des clients.

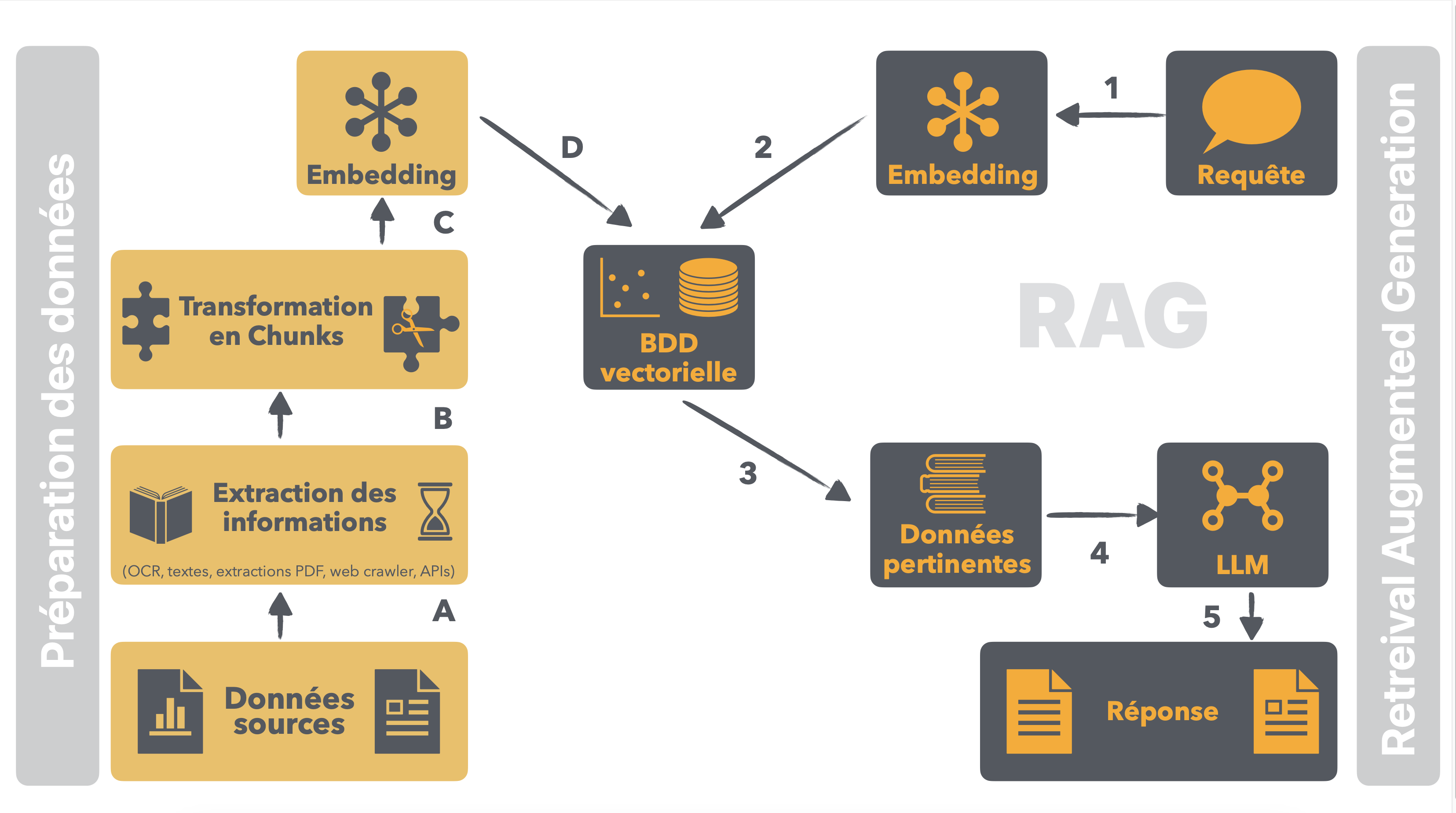
Le Workflow RAG Étape par Étape
Le RAG suit un enchaînement méthodique d’opérations pour transformer les données brutes en réponses pertinentes et informatives. Décortiquons ce processus :
Préparation des Documents
Avant toute chose, les informations sources (documents, pages web, PDF, APIs…) sont extraites et préparées pour un traitement optimal. Cette étape cruciale conditionne la qualité des données qui alimenteront le pipeline RAG.
Chunking et Embedding
Les données sont ensuite découpées en fragments plus petits, appelés « chunks », pour faciliter leur manipulation. Chaque chunk est alors converti en une représentation vectorielle, ou « embedding », qui capture son sens et son contexte de manière compacte.
Indexation dans une Base de Données Vectorielle
Les embeddings des chunks sont insérés dans une base de données vectorielle spécialisée. Cette structure de stockage optimisée permet des recherches par similarité rapides et précises, un atout majeur du RAG.
Transformation de la Requête
Lorsqu’un utilisateur soumet une requête, celle-ci subit le même processus d’embedding que les chunks, générant un vecteur de requête.
Retrieval des données pertinentes
Le système compare alors l’embedding de la requête avec ceux stockés dans la base de données vectorielle. Les chunks les plus proches (i.e. les plus similaires à la requête) sont récupérés pour constituer le contexte pertinent.
Génération de la Réponse par le LLM
Enfin, le LLM entre en jeu ! Il reçoit le contexte récupéré et génère une réponse informative et cohérente, tout en s’appuyant sur ses propres connaissances. Des techniques de « prompt engineering » permettent d’orienter le style et le format de la réponse.
Ce workflow, combinant retrieval de données, embedding et génération par LLM, confère au RAG sa puissance et sa précision. Il permet de tirer le meilleur des deux mondes : l’accès à l’information la plus à jour et la créativité des modèles de langage de pointe.
Boîte à outils du RAG : Les indispensables
- LangChain : Cet outil simplifie l’intégration des composants nécessaires pour construire un pipeline RAG efficace en se connectant à divers LLMs et en automatisant le workflow de retrieval à generation.
- LlamaIndex : Il permet d’indexer et de gérer les données en vue de leur récupération, jouant un rôle clé dans la première étape du processus RAG.
- Python : Le langage de prédilection pour orchestrer et implémenter des pipelines RAG grâce à sa simplicité et son écosystème riche en bibliothèques pour le traitement de données et l’apprentissage automatique.
Évaluation et Optimisation du RAG : Vers une performance globale
Évaluer un système RAG ne se résume pas à sa performance immédiate. Il faut adopter une approche holistique prenant en compte plusieurs aspects :
- Qualité de la Prédiction : La pertinence et la précision des réponses générées, mesurées par des métriques comme la précision, le rappel et le F1-score.
- Fiabilité : La véracité des informations retrouvées et leur adéquation avec la demande, évaluée par des tests de cohérence et de factualité.
- Performance Temporelle : La rapidité avec laquelle les réponses sont générées, analysée via des benchmarks de temps de réponse.
- Coût : L’impact financier et environnemental lié à l’utilisation des LLMs, optimisé par des techniques de compression de modèles et d’inférence efficace.
Pour évaluer et peaufiner le RAG, des frameworks comme RAGAS et TruLens fournissent des analyses détaillées des composantes retrieval et generation.
Pour finir…
Le RAG représente une avancée importante pour les entreprises cherchant à exploiter tout le potentiel des LLMs en générant des réponses précises et actualisées. Grâce à une compréhension fine et à l’utilisation stratégique d’outils spécialisés, les développeurs peuvent concevoir des systèmes capables de naviguer avec agilité dans l’ensemble des données de l’entreprise, ouvrant la voie à des applications innovantes et intelligentes qui répondent aux besoins présents et futurs des utilisateurs.
Le RAG n’est pas une simple tendance éphémère, mais bien un changement de paradigme qui redéfinit notre rapport à l’information générée par l’IA. En embrassant cette approche transformatrice, les entreprises se positionnent à l’avant-garde de l’innovation, prêtes à façonner un avenir où l’intelligence artificielle et l’expertise humaine se conjuguent harmonieusement pour créer de la valeur sans précédent.
Vous souhaitez en savoir plus sur la mise en place du RAG dans votre entreprise ? N’hésitez pas à nous contacter ou à vous inscrire à notre newsletter pour recevoir les dernières actualités et études de cas !