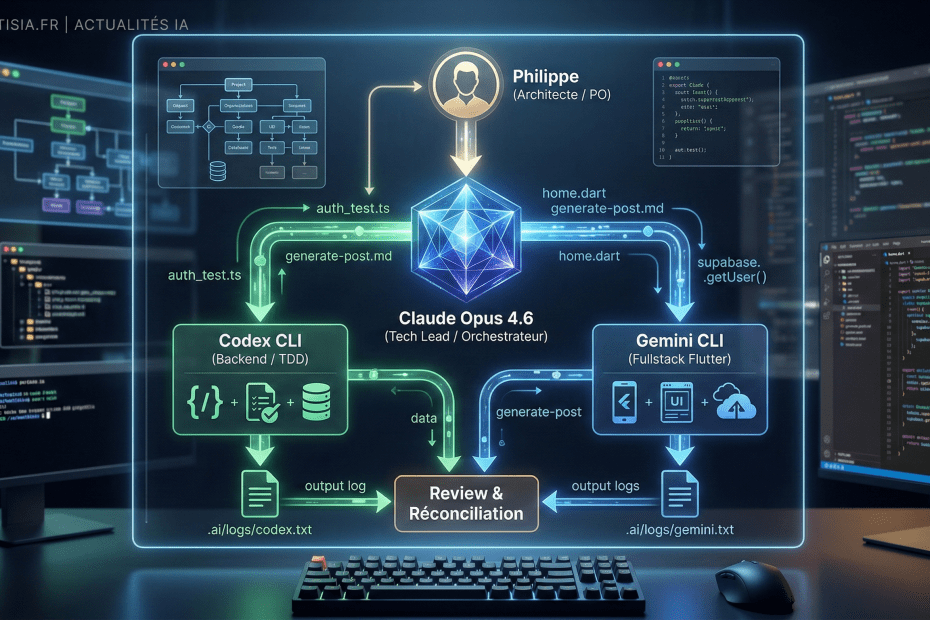
Comment j’ai configuré Claude Code pour orchestrer 3 IA (Claude, Codex CLI, Gemini CLI) en parallèle. Mémoire hybride, MCP servers, spec-driven development et retour d’expérience sur 3 projets.
Comment j’utilise Claude Code pour créer et gérer mes automatisations N8N : le guide complet
Temps de lecture : 15 minutes | Niveau : Intermédiaire à avancé
Il y a quelques mois, créer un workflow N8N de 31 nœuds me prenait plusieurs jours. Aujourd’hui, je confie la mission à Claude Code, et le workflow est créé, testé et déployé en une seule session — sans que j’aie besoin d’intervenir. Voici comment j’ai mis en place ce système, et pourquoi il change radicalement ma manière de travailler avec l’automatisation.
1. Pourquoi Claude Code (et pas ChatGPT, Cursor ou Copilot)
La question revient souvent : pourquoi ne pas simplement demander à ChatGPT de générer un workflow N8N ? Ou utiliser Cursor qui est aussi excellent pour coder ?
La réponse tient en un mot : l’agenticité.
Claude Code n’est pas un simple chatbot qui génère du texte. C’est un agent CLI autonome qui peut :
Exécuter des commandes sur votre machine
Appeler des APIs externes via les serveurs MCP (Model Context Protocol)
Lire et écrire des fichiers dans votre arborescence projet
Itérer en boucle jusqu’à obtenir le résultat attendu
Maintenir une mémoire persistante d’une session à l’autre
Concrètement, quand je demande à Claude Code de créer un workflow N8N, il ne se contente pas de me donner un JSON à copier-coller. Il se connecte directement à mon instance N8N, crée les nœuds, configure les connexions, valide le résultat, et corrige lui-même les erreurs qu’il détecte. Tout ça dans le terminal, sans interface graphique, sans intervention manuelle.
C’est cette capacité à agir, pas seulement conseiller, qui fait toute la différence.
La différence avec les autres outils
Critère
ChatGPT
Cursor/Copilot
Claude Code
Génère du JSON N8N
Oui
Oui
Oui
Déploie directement sur N8N
Non
Non
Oui (via MCP)
Valide le workflow
Non
Non
Oui (validation intégrée)
Corrige automatiquement
Non
Partiel
Oui (boucle itérative)
Mémoire inter-sessions
Limité
Non
Oui (fichiers mémoire)
Accès à la doc à jour
Non (cutoff)
Non
Oui (Context7 + NotebookLM)
Exécution shell
Non
Partiel
Oui (natif)
2. Le modèle : Claude Opus 4.6, le cerveau de l’opération
Mon setup utilise Claude Opus 4.6, le modèle le plus puissant de la famille Claude. Ce n’est pas un choix anodin : la création de workflows N8N complexes exige un niveau de raisonnement que les modèles plus légers ne peuvent pas fournir.
Pourquoi Opus et pas Sonnet ou Haiku ?
Un workflow N8N de 30+ nœuds implique de :
Comprendre l’architecture globale : quels nœuds, dans quel ordre, avec quelles dépendances
Maîtriser les détails techniques : le format exact des paramètres de chaque nœud, les différences entre versions d’API (Chat Completions vs Responses API par exemple)
Raisonner sur plusieurs étapes : si je modifie le nœud 10, quel impact sur les nœuds 11 à 18 ?
Débugger des problèmes subtils : comme le fait qu’un updateNode dans l’API N8N remplace tous les paramètres, pas seulement ceux qu’on envoie
Opus 4.6 excelle dans ce type de raisonnement en chaîne. C’est un investissement en tokens qui se rentabilise largement par le temps gagné et la qualité du résultat.
En pratique : J’utilise Opus pour la création et le debugging de workflows complexes. Pour des modifications simples (changer un texte, ajuster un paramètre), Sonnet 4.6 suffit amplement et coûte bien moins cher.
3. L’architecture MCP : 4 serveurs pour un pilotage total
Le Model Context Protocol (MCP) est la pièce maîtresse de ce setup. C’est un standard ouvert qui permet à Claude Code de se connecter à des services externes via des « serveurs MCP ». Pensez-y comme des plugins qui donnent à l’IA des super-pouvoirs spécialisés.
Mon installation repose sur 4 serveurs MCP qui, ensemble, couvrent 100% de mes besoins :
MCP #1 — Le serveur N8N : le bras armé
C’est le serveur le plus important. Il permet à Claude Code d’interagir directement avec mon instance N8N hébergée sur un VPS Hostinger via Docker.
Ce qu’il peut faire :
Lister, créer, modifier, supprimer des workflows — sans jamais ouvrir l’interface web
Rechercher des nœuds (search_nodes) — pour trouver le bon nœud parmi les centaines disponibles
Inspecter un nœud en détail (get_node) — pour connaître tous ses paramètres, versions et options
Valider un workflow (validate_workflow) — vérifier la structure, les connexions et les expressions avant de déployer
Déployer des templates — importer un template de la bibliothèque N8N et l’adapter
Tester l’exécution (n8n_test_workflow) — déclencher un workflow et analyser le résultat
Corriger automatiquement (n8n_autofix_workflow) — résoudre les problèmes courants de format d’expression ou de version de nœuds
C’est comme avoir un développeur N8N disponible 24h/24 qui peut non seulement concevoir, mais aussi exécuter et corriger en temps réel.
MCP #2 — Context7 : la documentation vivante
Un des plus gros problèmes avec les LLM, c’est la date de coupure des connaissances. Claude connaît N8N, mais pas forcément la dernière version du nœud OpenAI (v2.1) ou les changements récents d’API.
Context7 résout ce problème en donnant à Claude un accès en temps réel à la documentation officielle de N8N. Concrètement :
Plus de 1 500 snippets de documentation indexés et consultables
Score de fiabilité élevé (84/100) sur la source officielle /n8n-io/n8n-docs
Une source complémentaire avec 25 000+ snippets pour les recherches approfondies
Avant de configurer un nœud, Claude consulte automatiquement Context7 pour vérifier la syntaxe, les paramètres disponibles et les breaking changes récents. C’est ce qui lui permet de produire des configurations valides du premier coup, même sur des nœuds récemment mis à jour.
MCP #3 — NotebookLM : le RAG maison (j’y reviens en détail)
Google NotebookLM est utilisé comme une base de connaissances interrogeable par l’IA. J’ai créé un notebook dédié contenant toute ma documentation N8N enrichie : patterns d’agents IA, architecture Docker, expressions avancées, cas d’usage concrets. Claude le consulte avant chaque décision architecturale importante.
MCP #4 — Hostinger : le contrôle de l’infrastructure
Mon instance N8N tourne dans un container Docker sur un VPS Hostinger. Le MCP Hostinger permet à Claude Code de :
Consulter les logs du container pour diagnostiquer des erreurs
Redémarrer le container si nécessaire
Vérifier l’état du firewall et des DNS
Ça signifie que si un workflow échoue à cause d’un problème d’infrastructure, Claude peut diagnostiquer et résoudre le problème sans que j’intervienne — de l’analyse des logs au redémarrage du service.
L’orchestration des 4 MCPs
La vraie puissance vient de la combinaison. Voici le flux typique quand je demande à Claude de créer un workflow :
1. Context7 → Consulte la doc N8N à jour
2. NotebookLM → Vérifie les patterns et conventions du projet
3. N8N MCP → Recherche les nœuds, inspecte leurs paramètres
4. N8N MCP → Crée le workflow, le valide, le teste
5. Hostinger → Si erreur infrastructure, consulte les logs et corrige
6. N8N MCP → Corrige et redéploie jusqu'à succès
Ce pipeline est codifié dans mon fichier CLAUDE.md (j’en parle plus bas), ce qui signifie que Claude le suit automatiquement à chaque mission.
4. NotebookLM comme RAG : la mémoire institutionnelle de l’IA
C’est probablement l’aspect le plus original de mon setup. J’utilise Google NotebookLM comme un système RAG (Retrieval-Augmented Generation) pour Claude Code.
Le concept
Un RAG classique nécessite une base vectorielle, un pipeline d’indexation, du chunking… C’est complexe à mettre en place et à maintenir. NotebookLM offre tout ça gratuitement et sans code, avec en bonus le moteur de raisonnement de Gemini pour synthétiser les réponses.
Mon notebook N8N (ID : n8n-base-de-connaissances-comp) contient :
Patterns d’agents IA : les 5 architectures clés (Parent Agent, Prompt Chaining, Routing, Parallelization, Evaluator-Optimizer) avec des exemples N8N concrets
Intégration LLM : configurations détaillées pour OpenAI, Anthropic/Bedrock, avec les pièges à éviter
Architecture Docker : déploiement Docker Compose, scaling avec Redis, isolation et sécurité
Expressions avancées : JavaScript, JMESPath, Luxon — la syntaxe exacte pour les expressions N8N
Gestion d’erreurs : Error Trigger workflows, Stop And Error node, patterns de retry
Custom nodes : comment créer des nœuds TypeScript personnalisés
Cas d’usage réels : automatisation média IA, assistants Telegram/WhatsApp, génération de workflows par IA
Comment Claude l’utilise
Grâce au MCP NotebookLM, Claude peut interroger ce notebook en langage naturel pendant qu’il travaille :
ask_question(
notebook_id: "n8n-base-de-connaissances-comp",
question: "Quel pattern d'agent utiliser pour une recherche parallèle
suivie d'une fusion de résultats ?"
)
NotebookLM renvoie une réponse sourcée, que Claude intègre directement dans sa réflexion pour concevoir le workflow.
Le système de sessions
Le MCP NotebookLM supporte les sessions conversationnelles. Ça signifie que Claude peut poser plusieurs questions successives dans la même session, chaque réponse bénéficiant du contexte des questions précédentes :
Session 1: "Quels sont les patterns d'agent disponibles ?"
→ Vue d'ensemble des 5 patterns
Session 1: "Lequel est le plus adapté pour de la recherche multi-source ?"
→ Réponse ciblée avec contexte de la question 1
Session 1: "Montre-moi un exemple de Parallelization avec Perplexity"
→ Exemple concret construit sur les 2 réponses précédentes
C’est exactement le comportement d’un RAG, mais sans infrastructure à gérer.
Pourquoi pas un RAG classique ?
Critère
RAG classique (Pinecone, Weaviate…)
NotebookLM via MCP
Setup
Complexe (vectorDB, embeddings, chunking)
Upload de documents, c’est tout
Coût
$$$ (hébergement + embeddings)
Gratuit (100 notebooks)
Maintenance
Re-indexation, monitoring
Zéro
Qualité des réponses
Dépend du chunking
Gemini synthétise intelligemment
Mise à jour
Pipeline de réindexation
Ajouter/modifier une source
C’est une approche pragmatique qui convient parfaitement pour un usage individuel ou en petite équipe. Pour du scaling entreprise avec des millions de documents, un RAG dédié restera nécessaire.
5. La documentation comme fondation : CLAUDE.md et la mémoire persistante
Si les MCPs sont les bras de Claude Code, la documentation est son cerveau à long terme. Sans elle, chaque session repart de zéro. Avec elle, Claude sait exactement comment travailler sur mon projet.
Le fichier CLAUDE.md : les directives de mission
À la racine de mon projet, un fichier CLAUDE.md est automatiquement chargé à chaque session. C’est le « brief permanent » que Claude suit systématiquement. Voici ce qu’il contient :
# Projet N8N - Directives Claude Code
## MCP disponibles
- Description de chaque MCP et de son rôle
- Règles d'utilisation (ex: "Toujours appeler get_node
avec detail='standard' avant de configurer un nœud")
## Workflow de création d'un flow N8N
1. Consulter Context7 pour la doc N8N à jour
2. Consulter le notebook N8N dans NotebookLM
3. Rechercher les nœuds avec search_nodes
4. Configurer avec get_node (detail='standard')
5. Valider avec validate_workflow
6. Créer/déployer avec n8n_create_workflow
## Langue
Toujours répondre en français.
Ce fichier est la pièce la plus importante du setup. Il transforme Claude d’un assistant généraliste en un spécialiste N8N qui connaît mes conventions, mes outils et ma méthodologie.
La mémoire persistante : MEMORY.md
Au-delà du CLAUDE.md, Claude Code dispose d’un répertoire de mémoire persistante qu’il met à jour lui-même au fil des sessions. C’est un mécanisme natif de Claude Code qui permet à l’IA de :
Retenir les IDs de workflows existants pour ne pas les recréer
Documenter les problèmes résolus pour ne pas retomber dedans
Sauvegarder les patterns techniques découverts en cours de route
Tracker l’état du projet : quels credentials sont configurés, quels workflows sont actifs
Exemple concret de ce que Claude a retenu de lui-même :
# Problèmes résolus (mars 2026)
### Messages OpenAI vidés par updateNode (CRITIQUE)
- Cause : updateNode REMPLACE tout 'parameters'.
Mettre juste modelId → wipe les messages
- Fix : Toujours inclure TOUS les paramètres
dans chaque updateNode
### responses.values vs messages.values (CRITIQUE)
- OpenAI node v2.1 a DEUX modes :
- Chat Completions API → utilise messages.values
- Responses API (DÉFAUT v2.1) → utilise responses.values
- PIÈGE : Par défaut → Responses API
Ce mécanisme de mémoire fait que Claude ne commet jamais la même erreur deux fois. Quand il a découvert que l’API updateNode de N8N efface tous les paramètres non spécifiés (un bug qui m’aurait pris des heures à identifier manuellement), il l’a documenté. À la session suivante, il savait déjà comment l’éviter.
Les fichiers de mémoire thématiques
Pour les sujets complexes, Claude crée des fichiers de mémoire dédiés. Par exemple, tnm-workflow-optimizations.md contient tous les détails techniques du workflow newsletter : IDs des nœuds, problèmes rencontrés, patterns de référence croisée entre nœuds. Ce fichier fait office de documentation technique vivante du workflow.
6. Confier une mission : de l’instruction au workflow opérationnel
C’est là que la magie opère. Voici comment se passe concrètement une mission « création de workflow » :
Ce que je donne à Claude
Un brief en langage naturel. Pas de JSON, pas de spécification technique, pas de schéma. Exemple réel :
« Crée un workflow N8N qui automatise ma newsletter The Next Mind Tricks. Il doit chercher les actus IA de la semaine via Perplexity et GPT avec web search, faire une sélection éditoriale, générer le contenu section par section, assembler le tout en Markdown et sauvegarder le fichier. Utilise les prompts qui sont dans le dossier Perso_Hostinger/Newsletter TNM/. »
Ce que Claude fait (sans intervention)
Phase 1 — Recherche et compréhension
Lit les fichiers de prompts fournis pour comprendre le format attendu
Consulte Context7 pour la doc N8N à jour (nœuds HTTP Request, OpenAI, Code…)
Interroge NotebookLM pour les patterns d’architecture adaptés
Analyse les newsletters PDF existantes comme référence
Phase 2 — Conception
Propose un plan d’architecture (nombre de nœuds, phases, connexions)
Identifie les nœuds nécessaires via search_nodes
Inspecte chaque type de nœud via get_node(detail='standard')
Rédige le plan complet dans un fichier Markdown
Phase 3 — Création
Crée le workflow via l’API N8N avec tous les nœuds et connexions
Configure chaque nœud avec les bons paramètres
Valide le workflow avec validate_workflow
Corrige les erreurs de validation détectées
Phase 4 — Itération
Teste l’exécution du workflow
Analyse les résultats et les erreurs
Modifie les nœuds problématiques
Re-teste jusqu’à obtenir le résultat attendu
Documente les problèmes rencontrés dans sa mémoire
Le résultat
Un workflow de 31 nœuds répartis en 7 phases, fonctionnel, validé, avec une documentation technique complète. Le tout créé en quelques heures de travail autonome.
7. L’itération automatique : tester, corriger, redéployer sans intervention
C’est l’aspect qui impressionne le plus quand on le voit en action. Claude Code ne s’arrête pas à la première version : il boucle jusqu’à ce que ça marche.
Ce cycle se répète automatiquement. Voici des exemples réels de bugs que Claude a détectés et corrigés seul :
Bug #1 : Le contenu Tricks dérivait vers du générique
Symptôme : La section « Tricks de la semaine » ne parlait pas du sujet sélectionné. Diagnostic de Claude : Le nœud de recherche Perplexity recevait le texte complet de la sélection éditoriale au lieu du sujet Tricks spécifique. Correction : Remplacement de $json.selectionText par $json.tricksSubject dans la référence du nœud, plus ajout d’une instruction de fallback.
Bug #2 : Les paramètres OpenAI s’effaçaient à chaque mise à jour
Symptôme : Après une modification d’un nœud OpenAI, GPT répondait « Hello! How can I assist you? » — les prompts avaient disparu. Diagnostic de Claude : L’API updateNode de N8N remplace tous les paramètres, pas seulement ceux envoyés. En ne spécifiant que le modèle, les messages étaient écrasés. Correction : Inclusion systématique de tous les paramètres dans chaque appel updateNode. Et surtout : documentation dans la mémoire persistante pour ne plus jamais retomber dans ce piège.
Bug #3 : La mauvaise API OpenAI utilisée par défaut
Symptôme : Les nœuds OpenAI renvoyaient des réponses vides ou génériques. Diagnostic de Claude : Le nœud OpenAI v2.1 de N8N utilise par défaut la Responses API (nouveau) au lieu de la Chat Completions API. Les messages étaient configurés en messages.values alors qu’il fallait responses.values. Correction : Migration vers le bon format de paramètres. Un piège que même un développeur N8N expérimenté aurait pu mettre du temps à identifier.
Pourquoi c’est possible ?
Cette capacité d’itération repose sur trois piliers :
L’accès direct à l’API N8N via MCP — Claude peut modifier et retester sans friction
La validation automatique — chaque modification est vérifiée structurellement
La mémoire persistante — les erreurs passées ne se reproduisent pas
C’est un système qui s’améliore dans le temps. Plus Claude travaille sur le projet, plus sa base de connaissances s’enrichit, et moins il commet d’erreurs.
8. Cas réel : le workflow « TNM Newsletter Automatique »
Pour rendre tout ça concret, voici le workflow que Claude a créé et optimisé pour ma newsletter hebdomadaire sur l’IA, « The Next Mind Tricks ».
Le besoin
Générer automatiquement une newsletter de veille IA chaque semaine : 5 actus, 5 outils, 5 tendances, et un article « Tricks » approfondi de 600 mots. Le tout au format Markdown, prêt à être mis en page.
Recherche dual-source : Chaque catégorie est recherchée simultanément par Perplexity ET GPT avec web search. Ça maximise la couverture et la fraîcheur des résultats.
Sélection éditoriale IA : Un nœud GPT avec reasoning_effort: "high" sélectionne les meilleurs sujets parmi tous les résultats fusionnés, en appliquant des critères métier (impact business, accessibilité, pertinence France/Europe).
Déduplication multi-niveaux : Au niveau produit (pas entreprise), entre sections, et avec exclusion dynamique du sujet Tricks dans la section Outils.
QA automatique : Le dernier nœud GPT vérifie les doublons, la cohérence des dates, le respect des longueurs imposées, et flag les anomalies sans bloquer le pipeline.
Post-processing code : Des fonctions JavaScript dans les nœuds Code nettoient les URLs (suppression du tracking, extraction du domaine racine), corrigent le format gras/italique, et assemblent le Markdown final.
Les chiffres
31 nœuds au total
3,5 minutes d’exécution
0 warning QA à l’exécution #62
~600 mots de contenu structuré par exécution
8 newsletters produites avec ce workflow (#30 à #38)
9. Les limites et ce que j’ai appris
Ce setup n’est pas parfait. Voici les limites que j’ai rencontrées et les leçons tirées.
Ce qui ne fonctionne pas (encore) parfaitement
Les credentials : Claude ne peut pas configurer les clés API dans N8N pour des raisons de sécurité. C’est une étape manuelle obligatoire (OpenAI, Perplexity, Telegram…).
Le debugging visuel : Certains problèmes sont plus faciles à diagnostiquer dans l’interface graphique de N8N qu’en ligne de commande. Pour les workflows très visuels avec beaucoup de branches, l’éditeur N8N reste utile.
La consommation de tokens : Un workflow complexe peut nécessiter de longues sessions avec Opus. Il faut être conscient du coût et basculer sur Sonnet pour les tâches simples.
La dépendance aux MCPs : Si un serveur MCP est indisponible, Claude perd cette capacité. Pas de fallback automatique.
Les leçons clés
Investir dans le CLAUDE.md — C’est le fichier le plus rentable du projet. Chaque minute passée à le rédiger économise des heures de correction et de réexplication.
Laisser Claude documenter — La mémoire persistante est un outil puissant. Ne pas hésiter à laisser Claude écrire ses propres notes techniques.
Commencer simple, itérer — Plutôt que de spécifier un workflow de 30 nœuds d’un coup, donner le brief global et laisser Claude proposer l’architecture.
Alimenter le notebook NotebookLM — Plus le notebook contient d’informations pertinentes, meilleurs sont les résultats. C’est un investissement continu.
Utiliser la validation systématiquement — validate_workflow avant chaque déploiement, c’est non négociable. Ça évite les erreurs en production.
10. Comment commencer : le setup minimal
Vous voulez reproduire ce setup ? Voici le chemin le plus court.
Prérequis
Un compte Anthropic avec accès à Claude Code (API ou abonnement Max)
Une instance N8N (self-hosted ou cloud)
Un compte Google pour NotebookLM (gratuit)
Etape 1 : Installer Claude Code
npm install -g @anthropic-ai/claude-code
Lancez-le dans votre répertoire projet avec claude.
Etape 2 : Configurer le MCP N8N
Dans votre fichier de configuration MCP Claude Code, ajoutez le serveur N8N. Vous aurez besoin de l’URL de votre instance et d’une clé API N8N.
Etape 3 : Configurer Context7
Ajoutez le serveur MCP Context7 pour l’accès à la documentation. C’est un service gratuit qui indexe la documentation des bibliothèques open source.
Uploadez vos documents de référence N8N (tutoriels, patterns, documentation interne)
Partagez-le avec un lien public
Ajoutez-le dans votre configuration MCP NotebookLM
Etape 5 : Créer votre CLAUDE.md
C’est l’étape la plus importante. Créez un fichier CLAUDE.md à la racine de votre projet avec :
# Mon Projet N8N - Directives Claude Code
## MCP disponibles
[Liste de vos MCPs avec leur rôle]
## Workflow de création
1. Consulter Context7 pour la doc à jour
2. Consulter NotebookLM pour les conventions
3. Rechercher les nœuds avec search_nodes
4. Configurer avec get_node (detail='standard')
5. Valider avec validate_workflow
6. Créer/déployer
## Conventions
[Vos règles spécifiques]
## Langue
[Votre langue préférée]
Etape 6 : Lancez votre première mission
Commencez par quelque chose de simple :
« Crée un workflow N8N avec un webhook trigger qui reçoit un JSON, le transforme avec un nœud Code, et envoie le résultat sur Telegram. »
Observez comment Claude consulte la doc, recherche les nœuds, crée le workflow et le valide. C’est la boucle fondamentale sur laquelle tout le reste se construit.
Conclusion : l’automatisation de l’automatisation
Ce que j’ai construit, c’est en quelque sorte l’automatisation de l’automatisation. Au lieu de passer des heures dans l’interface N8N à glisser-déposer des nœuds, je décris ce que je veux en langage naturel et Claude Code s’occupe du reste.
Les ingrédients clés :
Un modèle puissant (Opus 4.6) pour le raisonnement complexe
Des MCPs bien choisis pour l’exécution directe
NotebookLM comme RAG pour la connaissance métier
Une documentation soignée (CLAUDE.md + mémoire) pour la continuité
Un cycle d’itération automatique pour la fiabilité
Le résultat ? Un workflow de newsletter de 31 nœuds, créé, testé et optimisé — avec une IA qui apprend de ses erreurs et ne les refait jamais. Ce n’est pas de la science-fiction, c’est mon quotidien depuis plusieurs mois.
Et le plus beau dans tout ça : pendant que Claude itère sur le workflow, je peux faire autre chose. L’IA travaille, je supervise. C’est un changement de paradigme dans la manière d’aborder l’automatisation.
Cet article vous a été utile ? Partagez-le avec quelqu’un qui s’intéresse à l’automatisation IA. Et si vous avez des questions sur le setup, n’hésitez pas à me contacter.
Les contenus visuels sont importants pour capter l’attention et renforcer les messages et l’intelligence artificielle (IA), elle, ne cesse de repousser les limites de la créativité numérique. Les entreprises, les créateurs de contenu et les développeurs cherchent constamment des solutions… Lire la suite »GPT-Image-1 : L’évolution ultime de la génération d’images par l’IA selon OpenAI
Découvrez Apple Intelligence: la révolution de l’intelligence personnelle pour iPhone, iPad et Mac, promettant confidentialité et intégration sans précédent.
OpenAI dévoile son Model Spec, un document ambitieux définissant le comportement éthique souhaité pour ses futurs modèles d’IA. Spécifiant des objectifs clés comme assister les humains et promouvoir le bien-être, il jette les bases d’une IA digne de confiance et alignée sur les valeurs humaines.
Découvrez le pouvoir du Retrieval Augmented Generation (RAG) pour surmonter les défis des modèles linguistiques, offrant des réponses précises et actualisées.
Les chiffres sont alarmants : selon la dernière édition du rapport AXA sur la santé mentale, 39% des salariés français déclarent vivre au moins cinq difficultés au travail, allant de la fatigue aux troubles du sommeil en passant par le… Lire la suite »L’IA et l’Automatisation au Secours du Bien-Être au Travail